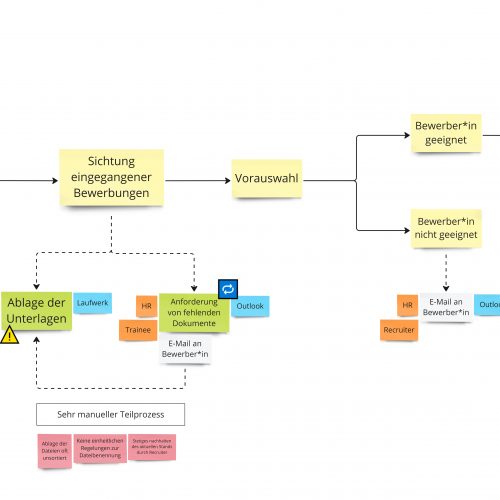
Blog Alle InhaltearchivAutomationCloud ERPData AnalyticsData OneHXMModern WorkplaceNew Work Digitale Organisation – Mit bedarfsorientierter Automatisierung HR Prozesse clever unterstützen6. Dezember 2023 Der Kampf gegen den Fachkräftemangel: Wie Microsoft Viva Unternehmen unterstützt27. November 2023 Use Case: Migration und Ablösung von Lotus Notes23. November 2023 Mehr als nur Tools: Microsoft Viva als Katalysator für Arbeits- und Unternehmenskultur16. November 2023 Eine Ode an Mitarbeiterumfragen – User Engagement, datenbasierte Entscheidungen & mehr19. Oktober 2023 Möglichkeiten der Arbeitszeiterfassung im SAP FSM28. April 2023 Datenschutz im SAP FSM – So schützen Sie die Einsatzzeiten vor unberechtigten Blicken30. März 2023 Design Thinking – ein modischer Begriff mit Daseinsberechtigung17. März 2023 Better Together: Data One und ORBIS vereinen HXM-Kompetenz in ORBIS People2. März 2023 Praktische Umsetzung: Agiles Change Management9. Januar 2023 SAP FSM im Überblick – ein teamübergreifender Wissensaustausch13. Dezember 2022 Mit Workflow Automation Fachkräftemangel entgegenwirken12. Dezember 2022 SAP SuccessFactors: Ein Blick hinter unsere digitalen HR-Prozesse1. Dezember 2022 Es braucht mehr Held:innen – Veränderungsprozesse durch Story Telling begleiten2. November 2022 Digitalförderung: Wegweiser und Chance für die digitale Transformation im Mittelstand21. Oktober 2022